엘라스틱 Enterprise 라이선스가 제공하는 비용혁신과 통합 로깅 전략 세미나
- 일시: 2025년 11월 12일(수) 09:00 ~ 12:30
- 장소: 롯데월드호텔 Emerald Room (3F)
세미나 대상
- 엘라스틱/오픈서치 인프라 비용 절감 방안을 찾고 계신 분
- LogsDB, 고압축 인덱스 등 최신 비용 최적화 기술에 관심 있으신 분
- GenAI 기반 엔터프라이즈 검색 도입을 고려 중이신 분
- 로그 데이터 관리 전략을 혁신하고 싶으신 분
요약
LogsDB, 고압축 인덱스 기술을 활용한 TCO 혁신 전략을 소개
소감
- 70%, 90% 등의 숫자는 Frozen tier 기준이므로, LogsDB 도입으로 인한 효과는 현실적으로 50% 내외 스토리지 절감으로 봐야할듯
압축으로 인한 절감이므로 처리속도가 진짜 더 개선됐는지, 속도 저하는 없는지 궁금함
- 후반부 세션은 벡터 검색에 대한 최신 기법 설명이 많아 좋았다. HNSW가 오래된 기술이 된 느낌이었다.

* 인사말
- Elasticsearch는 결국 대부분은 로깅으로 사용
- 어떻게 오픈소스 사용자를 상용으로 유입시킬 것인가?
최근 몇년은 Machine Learning 을 통해 유입많았으며 비용절감과 Vector DB를 통한 유입
* Agenda
1. 비용 절감
1) ES 소개: Cognitive Search, Analytics Platform, Security 등으로 소개
Security - EDR 라이선스에 포함
8.19 이후로는 9 버전으로 변경 예정
2) 상용제품으로의 ES 특장점
- Data Tiering
- LogsDB를 통한 디스크 사용 절감(8.17부터 도입)
- Machine Learning: 실시간 이슈 분석으로 초기 경고 신호 포착
- AIOps: 자동 해결
3) LogsDB를 통한 비용 절감
- 스토리지 사용 16% 절감
- indexing throughput 19% 증가
- 고객사 사례(금융):
- 보안 로그: Firewall, IPS 로그를 LogsDB로 사용해서 document 용량이 약 30% 감소
- 운영 로그: API, Enboy, Service 로그 용량 40~60% 감소
-> Storage 감소로 VM, N/W, Disk 등의 인프라도 함께 감소해 전체적으로 50~60% 이상 비용 절감
4) Searchable Snapshot
- Hot / Warm / Cold / Frozen
: Enterprise 라이선스에서만 제공하는 기능

벤치마크 자료들은 https://www.elastic.co/search-labs 참고

5) Machine Learning
- 이상징후 탐지: 단순 트래픽이 아니라 anomalous log 들도 분석 및 탐지 가능
--> mutable text 제외, 유사한 메시지 클러스터링
OpenSearch도 도입하려는 것으로 보임 (3.3부터)
https://docs.opensearch.org/latest/ml-commons-plugin/agents-tools/tools/log-pattern-analysis-tool/
- 금융사의 경우 FDS에 활용하기도 함
6) Elastic Observability
- AI Assistant 를 통해 바로 분석 가능: RAG 기반이기 때문에 더 정확한 답을 찾을 수 있다고 함
(인터넷 통한 호출이고 모델 변경을 통해 폐쇄망 가능한 듯)
2. Vector DB
1) Vector DB로써의 ES
- 8.12 이후 SIMD 명령어 기반 벡터 연산 개선으로 코사인 유사도 성능 개선
- 임베딩
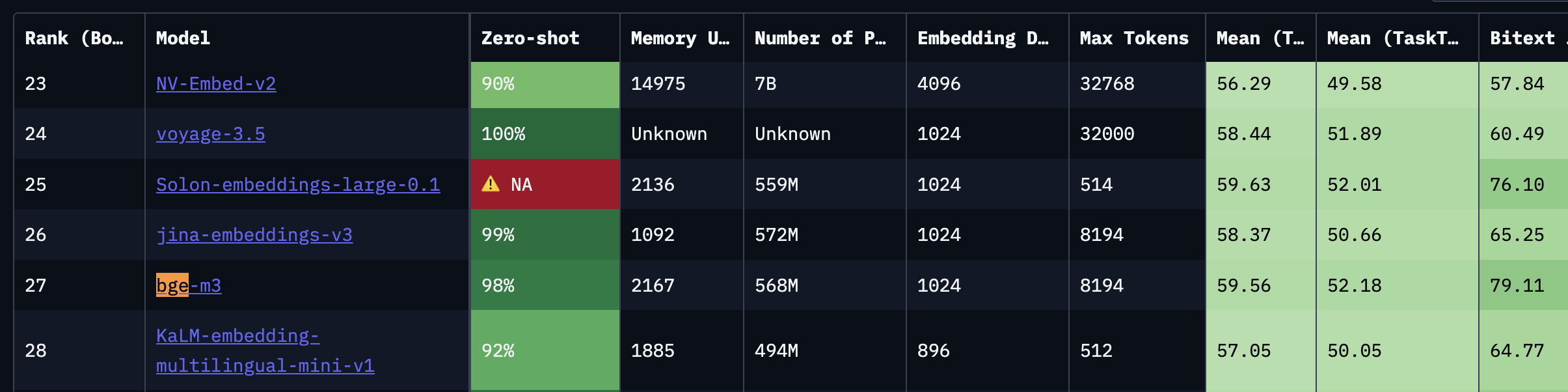
- 고려사항: 라이선스, 언어, max token, dimension(일반적으로 1,024 권장), 품질(도메인 지원, mteb 참고), 파라미터 수
- 모델 추천(25.11.12 기준): 한국어 텍스트의 경우 bge-m3 추천
멀티모달의 경우 siglip2 추천하지만 바로 임포트는 안 됨. Clip은 바로 import 되지만 2021년 모델
구축사례 참고: https://github.com/elastic/elasticsearch-labs
- 검색
- knn검색 핵심 파라미터: k, num_candidates (num_candidates = k * 1.5 권장)
- 하이브리드 검색: 한국어 임베딩 품질이 낮으므로 필요
- 가중 RRF 추가 (평점 0.5, 키워드 0.3, 시멘틱 0.2 등으로 가중치 넣어서 한 번에 검색)
- HNSW:

-> 벡터를 모두 메모리에 올려야하므로 컴퓨팅 자원이 많이 소모
-> 양자화가 필수적
- BBQ(Better Binary Quantization): 9.x 버전 핵심 기술
Float32 -> 1bit 양자화+ 14 Byte 보정 데이터
비대칭 양자화 (문서 1bit, 쿼리 int4), 비트 와이즈 내적을 수행해 초고속 검색 지원. OverSampling으로 극복
num_candidates 기본 3. 기존 int8 기본에서 9 버전부터 BBQ로 변경
2) Agentic AI 시대의 Elasticsearch
- MCP 도구 기반 Agentic RAG 구축 가능
- Standard RAG vs Agentic RAG
Standard RAG: 낮은 latency, 예산제약, 프로토타입/MVP
Agentic RAG: 정확도, 복잡한 소스, 여러 앱 재사용, 동적 도구 선택
-> 하이브리드 구성도 고려
- MCP 서버 구현 방법 2가지 (Kibana Agent Builder(베타), 직접 구현-SDK권장)
3) Elasticsearch의 미래 (9.1버전, 이후)
- DiskBBQ
| HNSW | DiskBBQ |
| 모든 벡터가 RAM에 존재 | 메모리 사용량 대폭 감소 (디스크 활용) |
| 메모리 부족시 성능하락 | 관련 클러스터만 검색해 성능 유지 |
| 인덱싱시 HNSW 그래프 탐색 | 대규모 벡터 처리 가능 |

https://www.elastic.co/search-labs/blog/diskbbq-elasticsearch-introduction
'아키텍처 Architecture > Software Architecture' 카테고리의 다른 글
| 책임연쇄패턴을 통한 로그 파싱 (chain-of-responsibility pattern) (1) | 2024.02.18 |
|---|---|
| Spring Boot HTTP, HTTPS 모두 사용하기 ( tomcat redirection ) (5) | 2022.02.20 |
| SpringBoot 무료 SSL 인증서 적용하기 (Certbot) (0) | 2022.02.19 |
| 금융IT와 MSA - 4. 도커 실습 - github (0) | 2022.01.29 |
| 금융IT와 MSA - 3. 도커 실습 - 설치&가동 (0) | 2022.01.21 |



